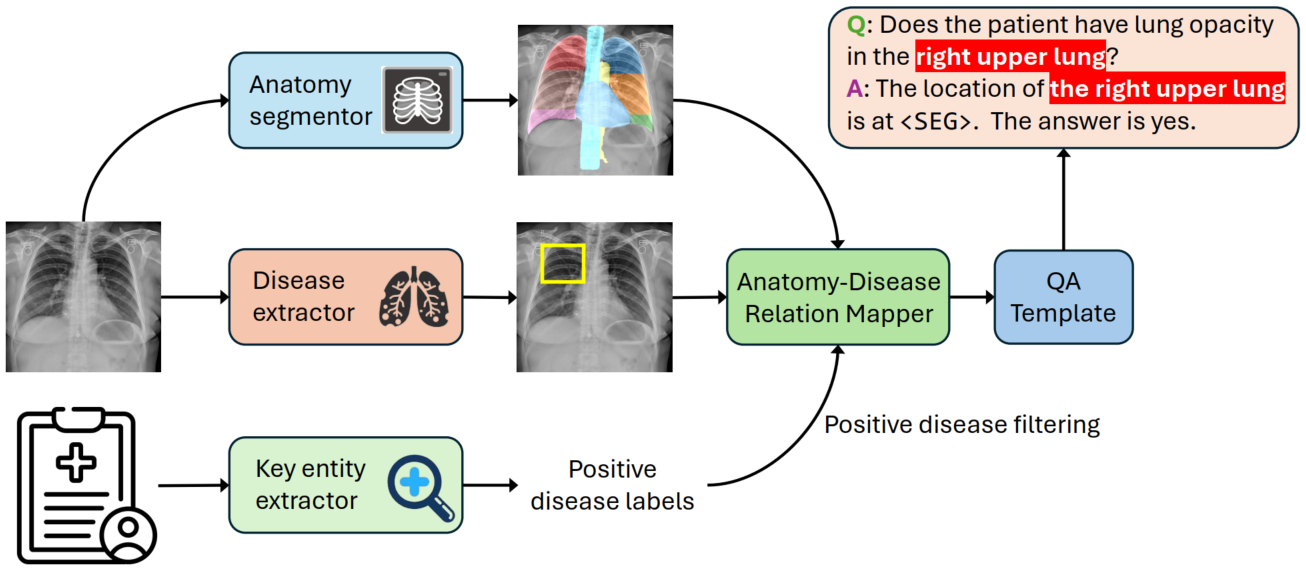
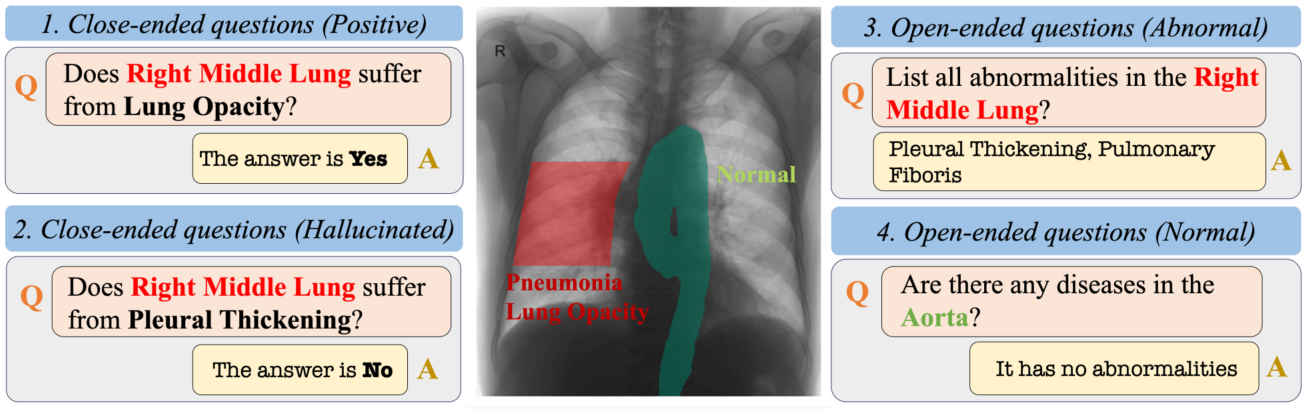
HEAL-MedVQA. We introduce HEAL-MedVQA (Hallucination Evaluation via Localization in Medical VQA), a benchmark designed to evaluate hallucination robustness and localization ability of medical LMMs using 67K doctor-annotated VQA pairs and anatomical segmentation masks.
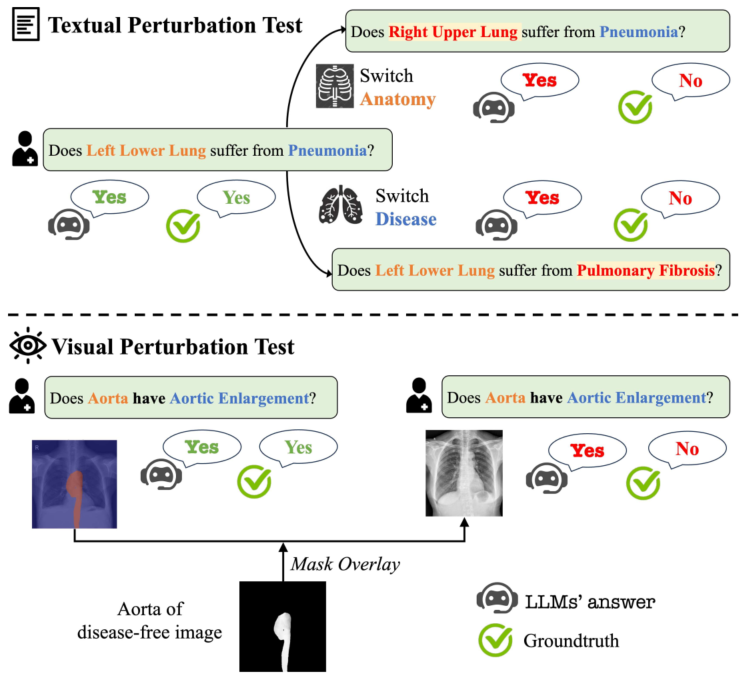
Evaluation Protocols. HEAL-MedVQA includes two protocols—Textual Perturbation Test (TPT) and Visual Perturbation Test (VPT)—to diagnose shortcut reliance on language or irrelevant image areas.
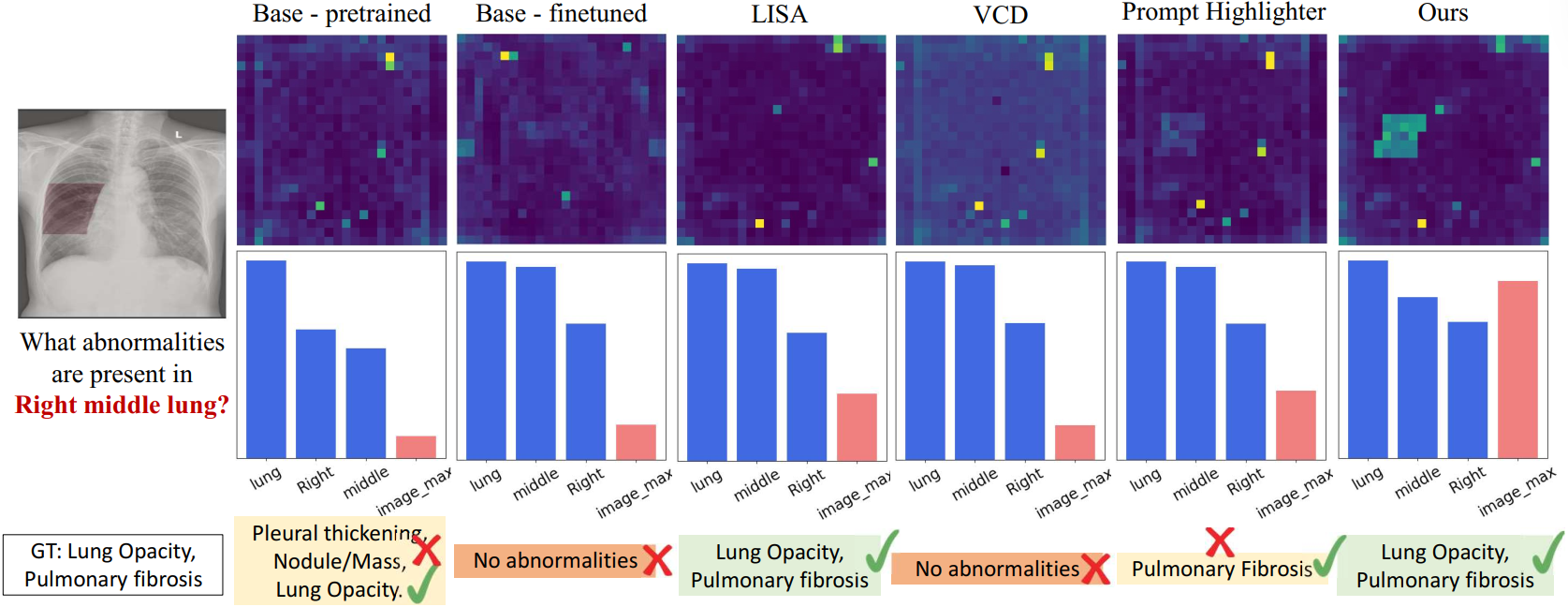
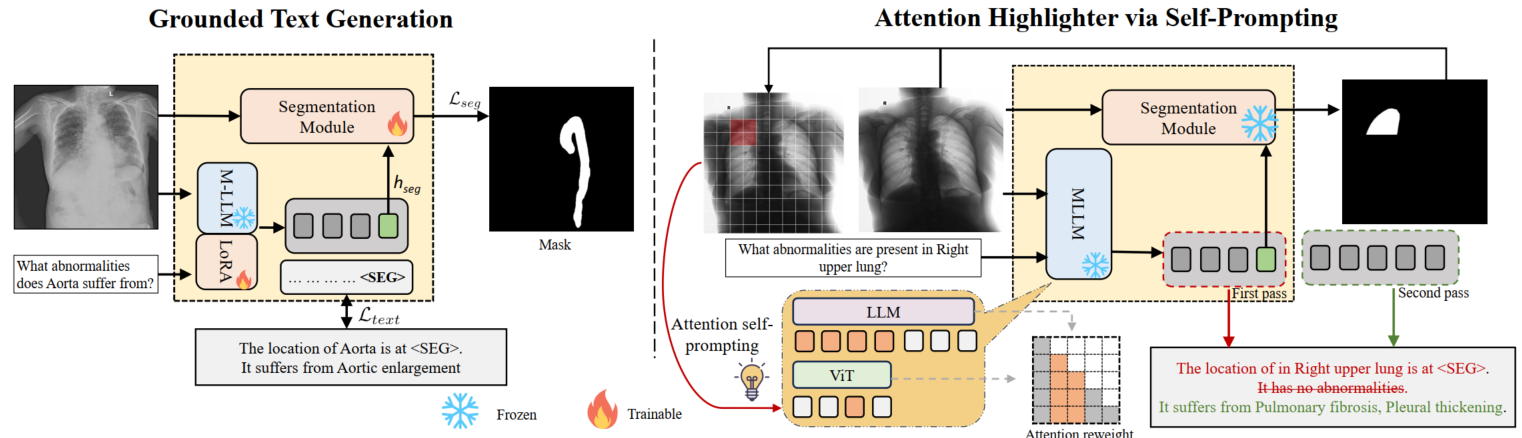
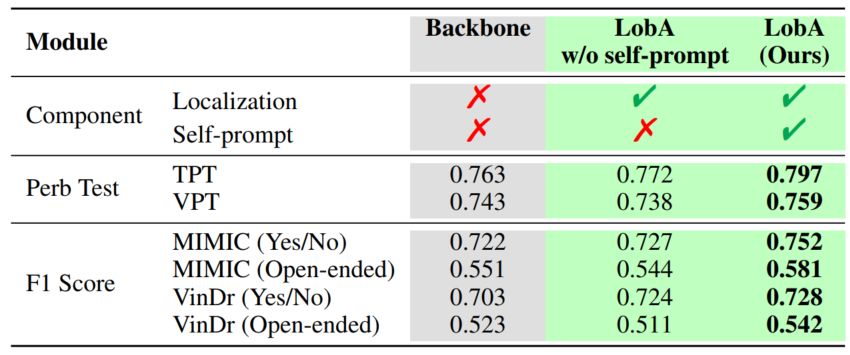
LobA Framework. We propose Localize-before-Answer (LobA), a method that improves visual grounding by training models to localize pathological regions and self-prompt for more accurate answers.
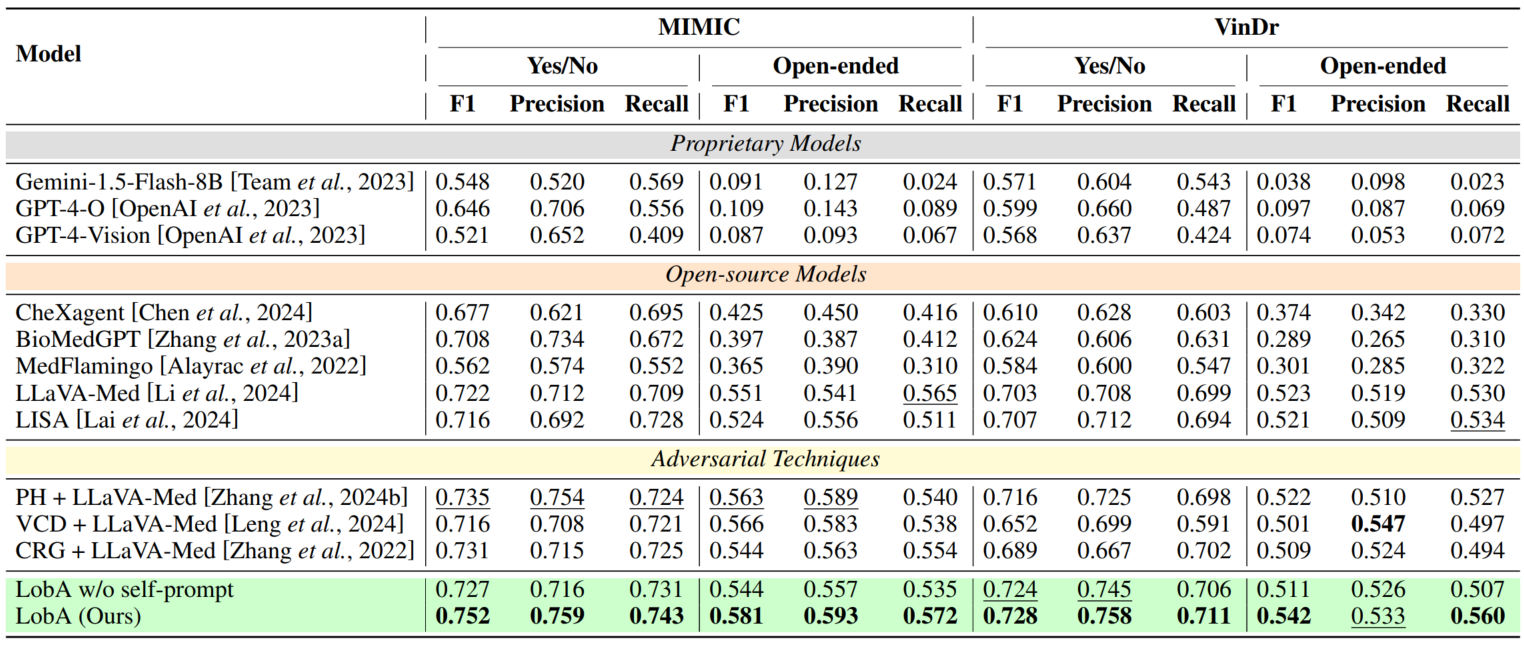
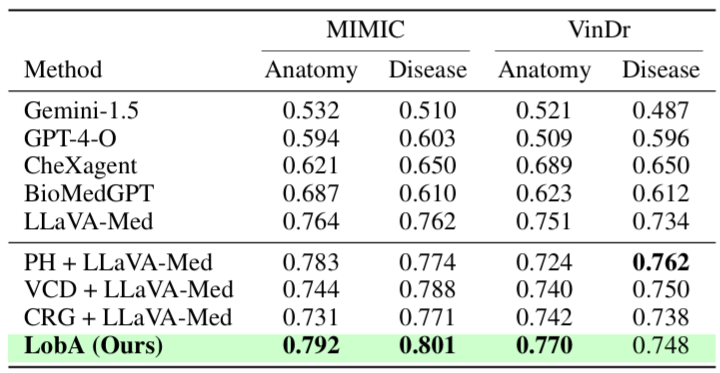
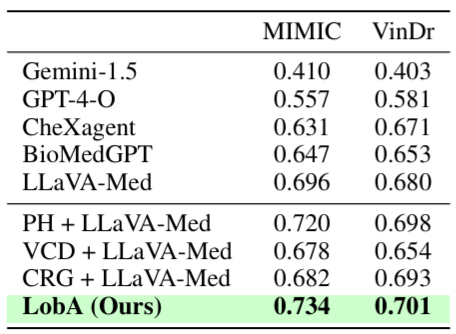
Performance. LobA significantly outperforms state-of-the-art medical LMMs on HEAL-MedVQA, advancing both robustness and reliability in medical VQA.